
M62 : Sécurité Linux « avancée » — Vue d’ensemble
Cette première partue fournit une vue d’ensemble des fonctionnalités de sécurité du noyau Linux. Après une brève description des mécanismes de sécurité standards du noyau, elle expose les principes adoptés pour étendre cette sécurité, et présente enfin les différentes extensions.
Sécurité Unix : Contrôle d’accès discrétionnaire
Linux a été développé au départ comme un clone du système d’exploitation Unix. De ce fait, il hérite du modèle de sécurité Unix — une forme de contrôle d’accès discrétionnaire (discretionary access control ou DAC). Les fonctionnalités de sécurité du noyau Linux ont considérablement évoluées depuis pour répondre à l’évolution des besoins ; cependant le modèle Unix DAC reste la fondation de la sécurité Linux.
En résumé, Le DAC Unix permet au propriétaire d’un objet (un fichier par exemple) de décider de la politique de sécurité qui s’applique à cet objet — c’est la raison pour laquelle il est qualifié de modèle discrétionnaire. En tant qu’utilisateur, vous pouvez, par exemple, créer un nouveau fichier dans votre répertoire personnel et décider qui peut lire ou écrire ce fichier. Cette politique est implémentée sous la forme de bits de permission associés à l’inode du fichier, qui peuvent être modifiés par le propriétaire du fichier. Les permissions d’accès au fichier, comme la lecture et l’écriture, peuvent être positionnées séparément pour le propriétaire, un groupe donné et les autres (le reste des usagers). C’est une forme relativement simple de liste de contrôle d’accès ou ACL (access contol list, cf M22-M24, droits POSIX).
Les processus initiés par un utilisateur s’exécutent avec tous les
droits de cet utilisateur, que l’ensemble de ces droits soient
nécessaires ou pas. Il existe aussi un super-utilisateur, ayant
l’identifiant (uid) 0, qui passe au travers des vérifications de la
politique DAC afin de pouvoir gérer le système. Lancer un programme en
tant que super-utilisateur fournit, de fait, au programme tous les
droits sur le système.
Étendre la sécurité Unix
Le DAC Unix est un modèle de sécurité relativement simple. Cependant, conçu en 1969, il ne répond plus aux besoins de sécurité actuels. Il ne protège pas le système de manière adaptée contre des logiciels défectueux ou mal configurés, qui pourraient être exploités par un attaquant pour accéder à des ressources sensibles. Les applications privilégiées, s’exécutant en tant que super-utilisateur (par conception ou pas), présentent un risque particulier dans ces conditions : Une fois compromises, elles sont susceptibles de fournir à l’attaquant un accès complet au système.
Les besoins de sécurité ont évolués au cours du temps. Par exemple, de nombreux usagers requièrent une politique plus fine que celle que fournit le DAC Unix, ou un mode de contrôle d’accès aux ressources qui n’est pas couvert par le DAC Unix comme c’est le cas du contrôle des flux réseau.
Il est essentiel de bien identifier une contrainte de conception critique pour l’intégration de nouvelles fonctionnalités dans le noyau Linux : les applications existantes doivent continuer à fonctionner. C’est une contrainte globale imposée par Linus pour toute nouvelle fonctionnalité. L’option consistant à concevoir un système de sécurité entièrement nouveau en partant de zéro n’est pas envisageable — les nouvelles fonctionnalités doivent être ajustées pour être compatibles avec la conception existante du système. D’un point de vue pratique, cela conduit à une collection d’améliorations de la sécurité plutôt qu’à une architecture de sécurité monolithique.
Extensions de la sécurité de Linux
Extensions du DAC
La plupart des premières extensions du modèle de sécurité Linux étaient des améliorations du DAC. Les Unix privateurs historiques ont chacun développé leurs propres améliorations, souvent très similaires les unes aux autres, et des efforts (infructueux) ont été fournis pour essayer de les standardiser.
ACL POSIX
Les listes de contrôle d’accès POSIX pour Linux sont fondées sur la
proposition 1e du standard POSIX. Elles étendent les ACL du DAC Unix
vers un modèle plus fin, permettant la mise en place de permissions
pour plusieurs utilisateurs et groupes. Elles sont gérées au travers
des commandes getfacl et setfacl. Les ACL sont enregistrées sur le
disque via les attributs étendus des fichiers, mécanisme extensible
destiné à stocker des meta-données avec les fichiers.
[olm@n306z-olm001 ~]$ ls -ld /tmp/ drwxrwxrwt 16 root root 360 14 oct. 14:04 /tmp/ [olm@n306z-olm001 ~]$ getfacl /tmp/ getfacl : suppression du premier « / » des noms de chemins absolus # file: tmp/ # owner: root # group: root # flags: --t user::rwx group::rwx other::rwx [olm@n306z-olm001 ~]$ sudo setfacl -m user:olm:rwx /tmp [olm@n306z-olm001 ~]$ getfacl /tmp/ getfacl : suppression du premier « / » des noms de chemins absolus # file: tmp/ # owner: root # group: root # flags: --t user::rwx user:olm:rwx group::rwx mask::rwx other::rwx [olm@n306z-olm001 ~]$ ls -ld /tmp/ drwxrwxrwt+ 16 root root 360 14 oct. 14:04 /tmp/ [olm@n306z-olm001 ~]$ # NOTEZ BIEN LE + FIGURANT APRÈS LES DROITS
Capacités POSIX
Les capacités POSIX (capabilities) sont elles-aussi basées sur une
proposition de standard. L’objectif principal de cette fonctionnalité
est de pouvoir réduire les privilèges associés au compte du
super-utilisateur, afin qu’une application requérant certains
privilèges ne les obtiennent pas nécessairement tous. Une application
peut s’exécuter avec un ou plusieurs sous-privilèges, comme
CAP_NET_ADMIN pour gérer les ressources réseau. Les capacités des
programmes peuvent être gérées avec les utilitaires getcap et
setcap. Il est possible de réduire le nombre d’applications
setuid du système en leur affectant les capacités adaptées,
toutefois, certaines capacités sont relativement globales et
fournissent un ensemble important de privilèges.
[olm@n306z-olm001 ~]$ ls -l $(which ping) -rwsr-xr-x 1 root root 56944 4 sept. 21:31 /usr/bin/ping [olm@n306z-olm001 ~]$ [olm@n306z-olm001 ~]$ # NOTEZ BIEN LE BIT SUID [olm@n306z-olm001 ~]$ [olm@n306z-olm001 ~]$ ping -c1 adminsyste.me PING adminsyste.me (198.245.62.141) 56(84) bytes of data. 64 bytes from olm.club (198.245.62.141): icmp_seq=1 ttl=51 time=103 ms --- adminsyste.me ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 103.827/103.827/103.827/0.000 ms [olm@n306z-olm001 ~]$ sudo chmod -s /usr/bin/ping [olm@n306z-olm001 ~]$ ls -l $(which ping) -rwxr-xr-x 1 root root 56944 4 sept. 21:31 /usr/bin/ping [olm@n306z-olm001 ~]$ [olm@n306z-olm001 ~]$ # PLUS DE BIT SUID [olm@n306z-olm001 ~]$ [olm@n306z-olm001 ~]$ ping -c1 adminsyste.me ping: socket: Opération non permise (raw socket required by specified options). [olm@n306z-olm001 ~]$ [olm@n306z-olm001 ~]$ # ÇA NE FONCTIONNE PAS SANS LES DROITS ROOT [olm@n306z-olm001 ~]$ [olm@n306z-olm001 ~]$ sudo setcap cap_net_raw+ep /usr/bin/ping [olm@n306z-olm001 ~]$ ping -c1 adminsyste.me PING adminsyste.me (198.245.62.141) 56(84) bytes of data. 64 bytes from olm.club (198.245.62.141): icmp_seq=1 ttl=51 time=100 ms --- adminsyste.me ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 100.872/100.872/100.872/0.000 ms
cf man 7 capabilities pour la liste et la fonction des capacités.
Quelques capacités
- CAP_AUDIT_CONTROL (since Linux 2.6.11)
- Enable and disable kernel auditing; change auditing filter rules; retrieve auditing status and filtering rules.
- CAP_AUDIT_READ (since Linux 3.16)
- Allow reading the audit log via a multicast netlink socket.
- CAP_AUDIT_WRITE (since Linux 2.6.11)
- Write records to kernel auditing log.
- CAP_CHOWN
- Make arbitrary changes to file UIDs and GIDs (see chown(2)).
- CAP_DAC_OVERRIDE
- Bypass file read, write, and execute permission checks. (DAC is an abbreviation of « discretionary access control ».)
- CAP_KILL
- Bypass permission checks for sending signals (see kill(2)). This includes use of the ioctl(2) KDSIGACCEPT operation.
- CAP_NET_ADMIN
- Perform various network-related operations:
- interface configuration;
- administration of IP firewall, masquerading, and accounting;
- modify routing tables;
- bind to any address for transparent proxying;
- set type-of-service (TOS)
- clear driver statistics;
- set promiscuous mode;
- enabling multicasting;
- use setsockopt(2) to set the following socket options: SO_DEBUG, SO_MARK, SO_PRIORITY (for a priority outside the range 0 to 6), SO_RCVBUFFORCE, and SO_SNDBUFFORCE.
- CAP_NET_BIND_SERVICE
- Bind a socket to Internet domain privileged ports (port numbers less than 1024).
- CAP_NET_RAW
- use RAW and PACKET sockets;
- bind to any address for transparent proxying.
- CAP_SYS_ADMIN
- Perform a range of system administration operations including: quotactl(2), mount(2), umount(2), swapon(2), swapoff(2), sethostname(2), and setdomainname(2)…
- CAP_SYS_BOOT
- Use reboot(2) and kexec_load(2).
Espaces de noms
Les espaces de noms (namespaces) sont issus du système d’exploitation Plan 9 (projet de recherche visant à succéder à Unix). C’est une technique légère permettant de partitionner les ressources mises à disposition des processus, afin qu’ils puissent, par exemple, disposer de leur propre vue des systèmes de fichiers montés ou même de la table des processus.
Ce n’est pas une pure fonctionnalité de sécurité, mais elle peut être
mise en œuvre pour améliorer la sécurité. Un exemple est le cas où
chaque processus peut être lancé avec son propre répertoire /tmp,
invisible des autres processus, ce qui fonctionne de manière
transparente avec le code existant de l’application et élimine tout un
pan de menaces sur la sécurité.
Les applications potentielles en sécurité sont diverses. Les espaces de noms sont utilisés pour faciliter la mise en œuvre d’une sécurité multi-niveaux (/cf SELinux), où les fichiers sont étiquetés avec une classe de sécurité, et potentiellement cachés des utilisateurs n’ayant pas les autorisations de sécurité appropriées.
Les namespaces sont aussi l’une des fondations de la technologie des conteneurs.
Il existe un espace de noms dédié pour chaque type de ressources à isoler :
- les identifiants de processus,
pid - les interfaces réseau,
network(cf sous-commande et optionnetnsde la commandeippour créer des VRF par exemple) - les noms d’hôte (un peu plus complexe à comprendre),
uts - les utilisateurs,
user - les points de montage,
mount - les communications inter-processus ,
ipc - les groupes de contrôle (cf ci-dessous),
cgroup
Exemple : en tant que root (privilège requis pour initier un nouvel
espace de nom), on peut déplacer un processus dans un nouvel espace de
pid (mount-proc est requis pour utiliser ps qui s’appuye sur
/proc).
olm@n306z-olm001$: sudo unshare --fork --pid --mount-proc bash root@n306z-olm001#: ps aux USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.0 0.1 22856 4660 pts/8 S 11:35 0:00 bash root 5 0.0 0.0 41028 3488 pts/8 R+ 11:36 0:00 ps aux root@n306z-olm001#: htop[…]
Les processus fils du nouveau shell ont leur propre espace de noms
pour les identifiants de processus (pid).
Dans un autre terminal :
olm@n306z-olm001$: ps auf | grep -v grep | grep -B4 htop olm 4492 bash root 4730 \_ sudo unshare --fork --pid --mount-proc bash root 4731 \_ unshare --fork --pid --mount-proc bash root 4732 \_ bash root 4781 \_ htop
On peut « entrer » dans l’espace de noms avec nsenter :
olm@n306z-olm001$: sudo nsenter --mount --pid -t 4732
[root@n306z-olm001 /]# ps ax
PID TTY STAT TIME COMMAND
1 pts/8 S 0:00 bash
25 pts/8 S+ 0:03 htop
34 pts/9 S 0:00 -bash
37 pts/9 R+ 0:00 ps ax
Il n’y a pas que les conteneurs pour la « virtualisation » de systèmes
qui utilisent les namespaces : lsns, =ls /proc/*/ns/=…
Sécurité réseau
Linux dispose d’une couche réseau très complète et performante supportant de nombreux protocoles et fonctionnalités. Linux peut aussi bien être utilisé comme hôte (terminaison du réseau) que comme routeur, autorisant le trafic entre ses interfaces selon la politique réseau.
La couche réseau de Linux fournit également une implémentation d’IPsec, qui assure la protection de la confidentialité, de l’authenticité et de l’intégrité du réseau IP par chiffrement. IPsec peut être utilisé pour implémenter des VPN (Virtual Private Network), et de la sécurité point-à-point.
Netfilter
Netfilter est le cadre de fonctionnement (framework) de la couche IP qui traite les paquets qui entrent, traversent et sortent du système. Des modules du noyau peuvent exploiter ce cadre pour examiner ces paquets et prendre des décisions à leur sujet.
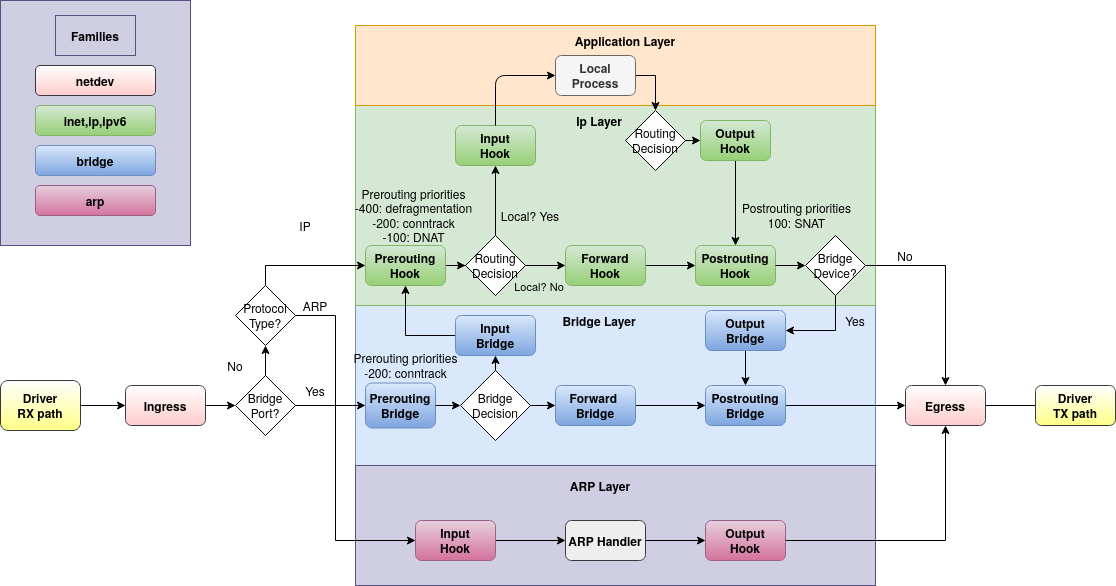
- TODO Intégrer https://portal.offensive-security.com/courses/pen-103/books-and-videos/modal/modules/securing-and-monitoring-kali-linux/firewall-or-packet-filtering/netfilter-behavior
iptables et son successeur nftables sont deux de ces modules, implémentant un modèle de filtrage réseau (firewalling) IPv4, piloté depuis les outils
iptablesetnftdans l’espace utilisateur. Des règles de contrôle d’accès pour les paquets IPv4 sont installés dans le noyau, et chaque paquet est confronté à ces règles afin de pouvoir traverser la couche réseau.iptablesetnftimplémentent également le suivi des paquets des protocoles à connexion (ex : TCP – stateful packet inspection) et la translation d’adresse. Le filtrage réseau sur IPv6 est implémenté de la même manière.À l’instar de
iptablesqui se charge du filtrage au niveau réseau, ebtables fournit le filtrage au niveau lien. Il est utilisé pour implémenter le contrôle d’accès des bridges Linux (switches virtuels). arptables fournit lui un filtrage des paquets ARP.Il peut être plus facile d’aborder le filtrage réseau en utilisant
iptables. Toutefois celui-ci devrait disparaître au profit denftablesdans les années à venir. La plupart des distribution permettent d’utiliser l’un ou l’autre des deux outils indifféremment pour piloter le filtrage effectué dans le noyau par Netfilter.
IPtables
Les principales actions (options) associées à la commande iptables
sont :
--appendou-A- ajouter une règle à la fin d’une chaîne
--insertou-I- ajouter une règle au début d’une chaîne
--deleteou-D- supprimer une règle en utilisant sa spécification ou son numéro
--listou-L- pour lister une ou plusieurs chaînes d’une table
Les deux principales tables sont filter et nat. La table filter
inclut les chaînes INPUT (paquets destinés à un processus local),
FORWARD (paquets à router) et OUTPUT (paquets issus d’un processus
local). La table nat inclut les règles PREROUTING (avant de
passer dans la table filter), OUTPUT (paquets issus d’un processus
local) et POSTROUTING (après la table filter).
Les principales options (à utiliser surtout avec les deux premières actions) sont les suivantes :
--tableou-t- spécifier la table concernée
--protocolou-p- spécifier le protocole concerné (ex : tcp)
--sourceou-s- spécifier le nom d’hôte, de réseau ou l’adresse source (éventuellement suffixée d’un masque de sous-réseau complet ou au format CIDR
--destinationou-d- spécifier le nom d’hôte, de réseau ou l’adresse destination
--in-interfaceou-i- spécifier l’interface d’entrée
--out-interfaceou-o- spécifier l’interface de sortie
--jumpou-j- spécifier la cible du paquet. Les deux
principales cibles sont
ACCEPTetDROP.
En dehors de la première et de la dernière, les options ci-dessus
peuvent être inversées en les préfixant par un !.
L’utilisation de certaines valeurs pour les options peuvent entraîner
la disponibilité de nouvelles options. Par exemple, avec -p tcp :
--source-portou--sport- spécifier le port source
--destination-portou--dport- spécifier le port destination
Des modules supplémentaires (extensions xtables) permettent
d’étendre les fonctionnalités intégrées d’iptables (ex : state).
Ils sont chargés avec l’option --match (ou -m).
Les options suivantes peuvent être utiles surtout avec l’action
principale --list :
--numericou-n- afficher adresses et numéros de port au format numérique
--verboseou-v- affichage détaillé
--line-numbers- affiche les numéros de ligne
NFtables : nft
- Intro
nftest en développement depuis 2009, pour remplaceriptablesvieillissant (une seule action par règle, rechargement à chaque modification, trop de modules, …).Depuis les versions 8 de CentOS 8 (juin 2020) et Buster de Debian, il remplace effectivement
iptables. - Actions
Les principales actions (options) associées à la commande
nftsont :list ruleset- afficher toutes les règles (utile pour la sauvegarde)
list tables- pour lister toutes les tables
list table <nom de la table>- pour lister toutes les chaînes d’une table
list chain <nom de la table> <nom de la chaîne>- pour lister une chaîne en particulier
add rule <nom de la table> <nom de la chaîne>- ajouter une règle après
insert rule <nom de la table> <nom de la chaîne>- ajouter une règle avant
delete rule <nom de la table> <nom de la chaîne>- supprimer une règle en utilisant sa spécification ou son numéro
flush rule <nom de la table>- supprimer toutes les règles d’une table
flush table- supprimer une table
- Tables
Les deux principales tables sont
ip filteretip nat(ipest implicite). La tableip filterinclut les chaînesINPUT(paquets destinés à un processus local),FORWARD(paquets à router) etOUTPUT(paquets issus d’un processus local). La tablenatinclut les chaînesPREROUTING(avant de passer dans la tablefilter),OUTPUT(paquets issus d’un processus local) etPOSTROUTING(après la tablefilter).NB : Chaque chaîne correspond à un hook dans le noyau.
- Spécification des paquets
Les principales options (à utiliser surtout avec les deux premières actions) sont les suivantes :
position <NUM>- préciser la position (ajout et suppression)
tcpouudp- spécifier le protocole concerné
ip saddr- spécifier le nom d’hôte, de réseau ou l’adresse source (éventuellement suffixée d’un masque de sous-réseau complet ou au format CIDR
ip daddr- spécifier le nom d’hôte, de réseau ou l’adresse destination
sport- spécifier le port source
dport- spécifier le port destination
iif- spécifier l’interface d’entrée
oif- spécifier l’interface de sortie
accept,drop,counter,log, …- spécifier la ou les cible⋅s du paquet
les options peuvent généralement être inversées en les préfixant par un
!.Les options suivantes peuvent être utiles surtout avec l’action principale
list:-n- afficher adresses et numéros de port au format numérique
-nn- affichage détaillé
-a- affiche les numéros de règles (handle)
———— Un petit TP ? ————
Cryptographie
Une API (Application Programming Interface) de cryptographie est fournie à l’usage des sous-systèmes du noyau. Elle propose un large éventail d’algorithmes cryptographiques et de modes opératoires, parmi lesquels les algorithmes de calcul d’empreinte (hash), de chiffrement symétrique (cyphers) et asymétrique. Il existe des interfaces synchrones et asynchrones, ces dernières étant utilisées pour gérer les matériels cryptographiques, qui déchargent les processeurs généralistes du traitement mathématique.
Le support des fonctionnalités de cryptographie s’appuyant sur le matériel se développe, et plusieurs algorithmes disposent d’implémentations optimisées en assembleur pour les architectures standards. Un sous-système de gestion des clés est fourni pour gérer les clés cryptographiques directement dans le noyau.
Les « utilisateurs » de l’API de cryptographie du noyau sont le code IPsec, les modules de chiffrement des disques parmi lesquels ecryptfs et dm-crypt, et le module noyau de vérification de signature.
LSM, modules de sécurité Linux
L’API des modules de sécurité Linux (LSM : Linux Security Modules) implémente des hooks (crochets) implantés dans tous les nœuds du noyau critiques d’un point de vue sécurité. Un logiciel « utilisateur » de ce cadre de travail (framewok) – un « LSM » – peut s’enregistrer grâce à l’API dédiée et recevoir des données via ces hooks. Les informations relatives à la sécurité sont alors passées au LSM, qui peut en retour interdire les opérations en cours. Ce mode de fonctionnement est similaire à celui de Netfilter, dont l’API est également fondée sur des hooks positionnés dans la couche réseau, bien que le principe des LSM soit appliqué au cœur du noyau et pas seulement dans la couche réseau.
L’API LSM permet la connexion de différents modèles de sécurité au noyau – généralement pour le contrôle d’accès. Pour assurer la compatibilité avec les applications existantes, les crochets sont positionnés de manière à ce que les vérifications DAC soient effectuées en premier, le code LSM n’étant invoqué que et si elles aboutissent.
SELinux et AppArmor sont les deux principaux LSM intégrés au noyau. D’autres modules comme Tomoyo, Smack ou Yama le sont également, cependant nous ne les détaillerons pas ici.
La technologie eBPF devrait rapidement servir de fondation à un nouveau LSM : https://fosdem.org/2020/schedule/event/security_kernel_runtime_security_instrumentation/
SELinux
Security Enhanced Linux (SELinux) est l’implémentation d’un contrôle d’accès obligatoire (MAC) fin, conçu pour répondre à une grande variété de besoins de sécurité, de l’utilisation générale, aux exigences des systèmes gouvernementaux et militaires exploitant des informations classifiées. La sécurité du MAC diffère de celle du DAC dans le fait que la politique de sécurité y est administrée de manière centrale, et que les utilisateurs ne décident pas de la politique concernant leurs ressources. Ce principe aide à contenir les attaques exploitant des bogues ou des défauts de configuration dans les logiciels de l’espace utilisateur.
Dans SELinux, tous les objets du système, comme les fichiers ou les processus, se voient affecter des étiquettes (labels). Toutes les interactions entre entités liées à la sécurité sont détournées par l’API LSM vers le module SELinux, qui consulte la politique de sécurité afin de déterminer si l’opération en cours peut se poursuivre. La politique de sécurité SELinux est chargée depuis l’espace utilisateur, et peut être modifiée pour répondre à différents objectifs de sécurité. De nombreux modèles de MAC antérieurs disposaient d’une politique figée, ce qui limitait leur application dans un cadre d’informatique générale.
SELinux est disponible sur la majorité des distributions et activé par défaut sur toutes celles fondées sur Fedora (soit RedHat Enterprise Linux et CentOS).
AppArmor
AppArmor est un modèle de MAC destiné au confinement d’applications et conçu pour être simple à gérer. La politique est configurée sous forme de profils applicatifs en utilisant une abstraction bien connue sous Unix : les chemins. AppArmor est fondamentalement différent de SELinux et Smack dans le fait qu’au lieu d’étiqueter des objets, la politique de sécurité est appliquée à des chemins. AppArmor dispose également d’un mode apprentissage, dans lequel le comportement d’une application peut être observé et converti automatiquement en profil de sécurité.
AppArmor est fourni avec Ubuntu (depuis 2012), OpenSUSE et Debian (depuis juillet 2019 avec la sortie de « Buster ») et largement déployé.
Audit
Le noyau Linux fournit un sous-système d’audit complet, conçu pour répondre aux besoins de certification gouvernementaux, qui présente certaines fonctionnalités utiles en tant que telles. Les LSM et d’autres composants de sécurité exploitent l’API d’audit du noyau. Les composants en espace utilisateur sont extensibles et très configurables.
Les journaux d’audit sont utiles pour l’analyse du comportement du système, et peuvent aider à la détection de tentative de compromission du système.
Seccomp
Seccomp (Secure computing mode), le mode de computation sécurisée est un mécanisme qui restreint l’accès aux appels système par processus. L’idée est de réduire la surface d’attaque du noyau en prévenant l’utilisation par les applications d’appels système dont elles n’ont pas besoin. L’API des appels système est une large passerelle vers le noyau, et comme dans tout code, il y a eu et il y a probablement encore, des bogues présents. Étant donnée la nature privilégiée du noyau, les bogues dans les appels système sont de potentielles voies d’attaque. Si une application n’a besoin que d’un sous-ensemble d’appels système, le fait de la restreindre à n’utiliser que ceux-là limite le risque global qu’une attaque aboutisse.
Le code seccomp original, connu sous le nom de « code 1 », fournissait
l’accès à seulement quatre appels système : read, write, exit et
sigreturn. Ces appels forment le minimum requis pour une application
utile, identifié alors pour être utilisé afin d’exécuter du code
inconnu sur des machines chargées.
Une mise à jour récente du code permet la spécification arbitraire des appels système autorisés pour un processus donné et l’intégration à la journalisation des audits. Ce « mode 2 » de seccomp a été développé dans le cadre de Google Chrome OS.
Gestion de l’intégrité
Le sous-système de gestion de l’intégrité du noyau peut être utilisé pour assurer l’intégrité des fichiers d’un système. L’architecture de mesure d’intégrité (IMA - Integrity Measurement Architecture) effectue des mesures de l’intégrité des fichiers en temps réel en utilisant leur empreinte cryptographique, les comparant avec une liste d’empreintes valides. Cette liste elle-même peut être comparée avec une empreinte agrégée stockée sur le TPM (Trusted Platform Module). Les mesures effectuées par l’IMA peuvent être journalisées au travers du sous-système d’audit, et également être utilisées pour une vérification d’authenticité, lorsqu’un système externe vérifie leur exactitude.
L’IMA peut aussi être exploitée pour la mise en œuvre d’une vérification d’intégrité locale en utilisant l’extension Appraisal. Les empreintes valides mesurées des fichiers sont stockées en tant qu’attributs étendus de ces fichiers, et donc vérifiées au moment de leur accès. Ces attributs étendus (ainsi que d’autres attributs étendus relatifs à la sécurité) sont protégés contre les attaques hors ligne par le module de vérification étendu (EVM, Extended Verification Module), idéalement en conjonction avec le TPM. Si un fichier a été modifié, l’IMA peut être configurée via la politique pour en interdire l’accès. La mise en œuvre de l’extension de signature numérique (Digital Signature) permet à l’IMA de vérifier l’authenticité des fichiers en plus de leur intégrité en contrôlant les empreintes signées des mesures.
Une approche plus simple de la gestion de l’intégrité est le module dm-verity. C’est une cible du mappeur de périphériques qui gère l’intégrité des fichiers au niveau bloc. Il est prévu pour être utilisé dans le processus de démarrage, pendant lequel un appelant proprement autorisé active un périphérique, comme une partition contenant des modules à charger ultérieurement. L’intégrité de ces modules sera vérifiée de façon transparente bloc par bloc lors de leur lecture depuis le disque.
NB: Même sudo peut assurer l’intégrité de certains exécutables :
https://fosdem.org/2020/schedule/event/security_what_you_most_likely_did_not_know_about_sudo/attachments/slides/3733/export/events/attachments/security_what_you_most_likely_did_not_know_about_sudo/slides/3733/CzP_sudo_sec_v2.pdf
Durcissement et sécurité de la plateforme
Différentes techniques de durcissement sont appliquées à divers niveaux, en particulier dans la chaîne de compilation et dans le logiciel, afin de réduire le risque d’une compromission du système.
La randomisation de l’espace d’adressage place les diverses parties de la mémoire d’un exécutable de l’espace utilisateur dans des endroits aléatoires, ce qui aide à prévenir certains types d’attaques. Ceci a été adapté des projets externes PaX et grsecurity, ainsi que de nombreux autres fonctionnalités logicielles de durcissement.
Le noyau Linux présente également des fonctionnalités de sécurité matérielles lorsqu’elles sont disponibles, comme NX, VT-d, le TPM, TXT, et SMAP, en plus du support du traitement cryptographique matériel déjà évoqué.
En résumé
Cette partie couvre, à très haut niveau, la façon dont la sécurité du noyau a évolué depuis ses racines Unix, s’adaptant aux exigences de sécurité toujours changeantes. Ces exigences sont issues d’évolutions extérieures, comme l’accroissement continu de l’internet et la valeur grandissante de l’information stockée en ligne, et aussi de l’agrandissement incessant de la base des utilisateurs de Linux.
S’assurer que les fonctionnalités de sécurité du noyau Linux continuent de répondre à une telle variété de besoins dans un paysage changeant est un défi continu de progrès.